 |
|
 |
NOTICE: This page is no longer mantained. Please check the new home page.
Treinamento das ESN
Jaeger (2002) apresenta informalmente os princípios das ESN mostrando como treinar uma rede neural para gerar uma onda senoidal:
A onda desejada é dada por ![]() . Esta tarefa não envolve entrada, portanto teremos uma rede
sem nenhuma entrada, e com uma única saída que após o treinamento produzirá
. Esta tarefa não envolve entrada, portanto teremos uma rede
sem nenhuma entrada, e com uma única saída que após o treinamento produzirá ![]() . O sinal "professor" é uma seqüência de 300 passos de
. O sinal "professor" é uma seqüência de 300 passos de ![]() .
.
Inicialmente é construída uma rede recorrente com 20
neurônios, cujos pesos das conexões internas ![]() são inicializados com
valores aleatórios e não muda durante o treinamento. Esta rede é chamada de
"reservatório dinâmico". Os neurônios são sigmoidais com função de ativação
são inicializados com
valores aleatórios e não muda durante o treinamento. Esta rede é chamada de
"reservatório dinâmico". Os neurônios são sigmoidais com função de ativação ![]() .
.
Essa construção usando valores aleatórios para ![]() poderia fazer com que
a rede apresentasse um comportamento oscilatório ou mesmo caótico, e isso não é
o desejado. A solução é usar valores baixos para
poderia fazer com que
a rede apresentasse um comportamento oscilatório ou mesmo caótico, e isso não é
o desejado. A solução é usar valores baixos para ![]() , quanto mais baixos esses pesos, mais a rede tende a
converger para um estado zero iniciando a partir de qualquer estado arbitrário.
Assumimos então uma inicialização de
, quanto mais baixos esses pesos, mais a rede tende a
converger para um estado zero iniciando a partir de qualquer estado arbitrário.
Assumimos então uma inicialização de ![]() com valores baixos, a
Figura 1 mostra o gráfico da saída dos 20 neurônios quando iniciados com um
valor aleatório
com valores baixos, a
Figura 1 mostra o gráfico da saída dos 20 neurônios quando iniciados com um
valor aleatório ![]() .
.

Figura 1. Dinâmica dos neurônios no reservatório dinâmico.
Adicionamos um único neurônio de saída para este
reservatório. Esta saída tem conexões que projetam de volta para o
reservatório. A estas retroprojeções são atribuídos pesos aleatórios ![]() , que também são fixos e não mudam durante o treinamento. O
neurônio de saída é linear.
, que também são fixos e não mudam durante o treinamento. O
neurônio de saída é linear.
As únicas conexões que são modificadas durante o aprendizado
são as do reservatório para o neurônio de saída, cujos pesos são dados por ![]() . Esses pesos não são definidos nem usados durante o
treinamento. A Figura 2 mostra a rede preparada para o treinamento.
. Esses pesos não são definidos nem usados durante o
treinamento. A Figura 2 mostra a rede preparada para o treinamento.
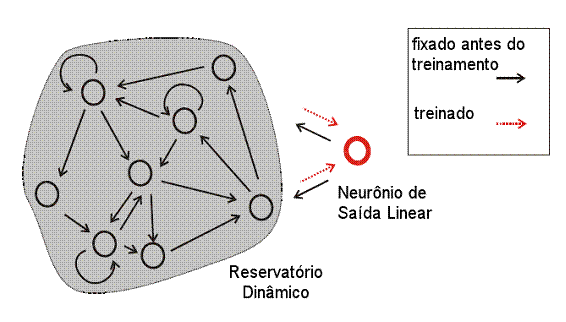
Figura 2. Configuração da ESN para treinar o gerador de ondas senoidais
O treinamento é feito em duas etapas: amostragem e computação de pesos. Veremos estas duas etapas a seguir.
Amostragem
Durante a fase de amostragem, o sinal professor é na unidade
de saída para os tempos ![]() . A rede é iniciada no passo
. A rede é iniciada no passo ![]() com um estado arbitrário
(aqui usaremos o estado zero). O sinal professor
com um estado arbitrário
(aqui usaremos o estado zero). O sinal professor ![]() é bombeado no
reservatório através das conexões de retroprojeção
é bombeado no
reservatório através das conexões de retroprojeção ![]() e, portanto estimula
uma dinâmica de ativação dentro do reservatório. A Figura 3 mostra o que
acontece dentro do reservatório nos passos
e, portanto estimula
uma dinâmica de ativação dentro do reservatório. A Figura 3 mostra o que
acontece dentro do reservatório nos passos ![]() .
.

Figura 3. As saídas de cada um dos 20 neurônios do reservatório
induzidas por um sinal professor ![]() no neurônio de saída
(último gráfico).
no neurônio de saída
(último gráfico).
Neste ponto é importante observar que os padrões de ativação dentro do reservatório são periódicos, cujos períodos têm a mesma freqüência do sinal professor, e que estes padrões diferem um dos outros dentro do reservatório.
Durante o período de amostragem, os sinais internos ![]() para
para ![]() são coletados nas linhas de uma matriz
são coletados nas linhas de uma matriz ![]() de tamanho 200x20. Ao
mesmo tempo, as saídas do professor
de tamanho 200x20. Ao
mesmo tempo, as saídas do professor ![]() são coletadas nas
linhas de uma matriz
são coletadas nas
linhas de uma matriz ![]() de tamanho 200x1.
de tamanho 200x1.
Não são coletados dados de ![]() , porque nesses passos iniciais a dinâmica da rede é
parcialmente determinada pelos estados iniciais arbitrários. No passo
, porque nesses passos iniciais a dinâmica da rede é
parcialmente determinada pelos estados iniciais arbitrários. No passo ![]() é seguro afirmar que
os efeitos da inicialização arbitrária já desapareceram e que os estados da
rede são determinados apenas por
é seguro afirmar que
os efeitos da inicialização arbitrária já desapareceram e que os estados da
rede são determinados apenas por ![]() como mostrado na
Figura 3.
como mostrado na
Figura 3.
Computação de Pesos
Agora chegou a hora de computar os
20 pesos de saída ![]() para nosso neurônio
linear de saída
para nosso neurônio
linear de saída ![]() tais que a saída do
professor
tais que a saída do
professor ![]() seja aproximada como
uma combinação linear das séries de ativação internas
seja aproximada como
uma combinação linear das séries de ativação internas ![]() por
por
![]() .
.
De maneira mais específica ,
computamos os pesos ![]() tais que o erro de
treinamento quadrático médio
tais que o erro de
treinamento quadrático médio
![]()

é minimizado.
Do ponto de vista matemático esta é uma tarefa de regressão
linear, que consiste em computar os pesos de regressão ![]() para uma regressão de
para uma regressão de ![]() nos estados da rede
nos estados da rede ![]() com
com ![]()
De um ponto de vista intuitivo-geométrico, isto significa combinar os 20 estados internos vistos na Figura 3 de forma que a combinação resultante melhor aproxime o sinal do professor visto na mesma figura (o último).
E finalmente do ponto de vista algorítmico, a computação offline dos pesos de regressão equivalem
a computar uma pseudoinversa: os pesos desejados que minimizam
![]() são obtidos
multiplicando a pseudoinversa de
são obtidos
multiplicando a pseudoinversa de ![]() com
com ![]() :
:
![]() .
.
Computar a pseudoinversa de uma matriz é uma operação padrão
na álgebra linear. Neste exemplo, o erro de treinamento com os pesos ótimo foi ![]() . Uma vez calculados os pesos, estes são inclusos na rede, a
qual estará pronta para uso.
. Uma vez calculados os pesos, estes são inclusos na rede, a
qual estará pronta para uso.
Utilização
Após os pesos de saída serem escritos nas conexões de saída,
a rede foi executada por mais 50 passos, continuando do último estado de
treinamento ![]() , porém agora a saída do professor não será mais utilizada.
Dessa forma a saída da rede
, porém agora a saída do professor não será mais utilizada.
Dessa forma a saída da rede ![]() passa a ser gerada
pela própria rede treinada.
passa a ser gerada
pela própria rede treinada.
O erro de teste:
![]()
foi
encontrado ![]() , que é maior que o erro de treinamento, mas ainda bastante
pequeno, mostrando que a rede aprendeu a gerar a onda senoidal de forma precisa.
, que é maior que o erro de treinamento, mas ainda bastante
pequeno, mostrando que a rede aprendeu a gerar a onda senoidal de forma precisa.
É
possível afirmar, portanto, que o sinal ![]() é obtido através de
seus próprios ecos
é obtido através de
seus próprios ecos ![]() .
.
Para mostrar que a estabilidade obtida não está no fato de
os passos avaliados começarem em ![]() , que é gerado pela saída do professor, Jaeger (2002)
inicializa a rede treinada a partir de um estado arbitrário, e mesmo assim após
alguns passos ela se estabiliza no sinal desejado, conforme mostrado na Figura
4.
, que é gerado pela saída do professor, Jaeger (2002)
inicializa a rede treinada a partir de um estado arbitrário, e mesmo assim após
alguns passos ela se estabiliza no sinal desejado, conforme mostrado na Figura
4.

Figura 4. Iniciando a rede treinada a partir de um estado aleatório. O gráfico mostra as primeiras 50 saídas.
Bibliografia
H. Jaeger (2002): Tutorial on training recurrent neural networks,
covering BPTT, RTRL, EKF and the "echo state network" approach.
GMD Report 159,
"Para que o manifeste, como me convém falar." (Cl 4:4)
Webdesigner:
Fabricio Breve 1997 - 2003
[email protected] - Privacidade